- OptionZero는 기존 MuZero 알고리즘에 "옵션(option)" 네트워크를 결합하여, 에이전트가 환경과의 상호작용(self-play)을 통해 스스로 옵션(일련의 행동 시퀀스)을 발견하고 이를 활용해 더 효율적으로 플래닝(planning)하도록 만든 강화학습 방법
- 이 옵션은 미리 정의하거나 전문가 데이터에 의존하지 않고, 자율적으로 학습이 가능함.
- MuZero와 달리 옵션을 직접적으로 탐색/계획에 사용하고, 옵션이 길어져도 환경 시뮬레이션 비용이 크지 않도록 동적 네트워크 구조를 개선함.
Background
- 옵션(option)은 primitive action(단일 행동)을 여러 번 반복하거나 복합적으로 묶은, 시간적으로 확장된 행동임(= temporally extended action)
- 예시: "미로에서 직진하다가 코너에 도달하면 멈춘다"는 한 스텝씩 가는 것보다 효율적임.
- 기존 연구는 옵션을 미리 정하거나, 전문가 데이터를 통해 학습시켰지만, 범용성이나 실제 적용이 제한됨.
MuZero
- MuZero는 AlphaZero 기반으로, 환경의 전이(transition)를 nn으로 예측하여, 실제 환경과의 상호작용을 최소화 하였음.
- Monte Carlo Tree Search(MCTS)로 플래닝을 하며, representation, dynamics, prediction의 네트워크로 구성됨.
OptionZero
- Muzero + Option Network: 각 상태에서 실행할 만한 옵션(action sequence)을 예측하는 네트워크를 추가
- 각 옵션은 현재 상태에서 실행 가능한 primitive action들의 조합이며, 옵션의 확률을 누적곱으로 계산하여, "dominant option"(가장 실행 확률이 높은 옵션)을 구함.
- 옵션 길이가 길어질 수록 후보 수가 기하급수적으로 늘어날 수 있지만, dominant option만 선택하여 효율적으로 학습함.
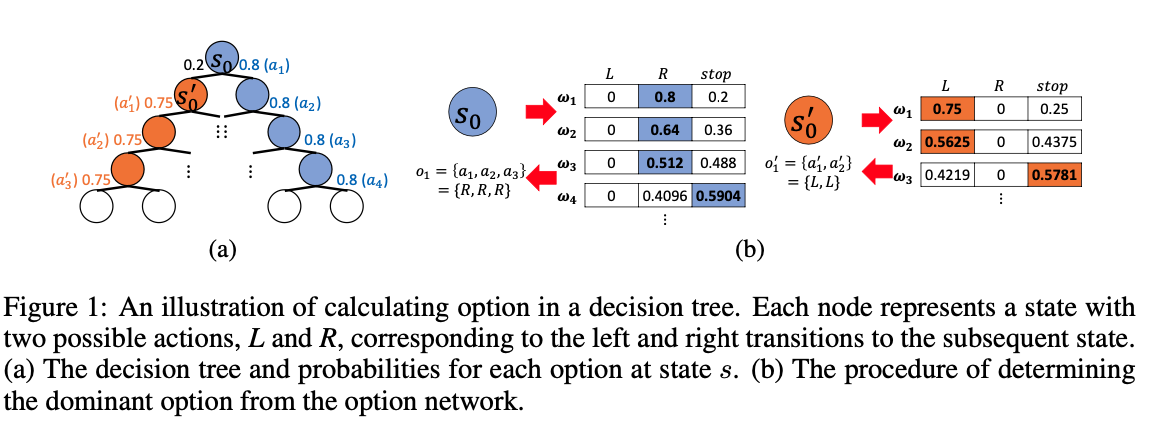
기존 MuZero의 MCTS에 옵션 노드(옵션으로 여러 state를 한 번에 뛰어넘는 edge)를 추가해서 플래닝 단계에서 옵션을 쓸 수 있게 함.
primitive action과 option을 동시에 고려해서, 경우에 따라 옵션을 선택하거나, 기본 행동을 선택함.
dynamics 네트워크도 여러 스텝짜리 옵션을 한 번에 처리할 수 있도록 개선
Option이란?
일련의 primitive action sequence.
dominant option에만 관심이 있다.
Training
- MuZero처럼 self-play 데이터를 모아 replay buffer에 저장, K스텝 unroll하며, 각 네트워크를 end-to-end로 업데이트
- 옵션 네트워크는 실제 환경에서 실행한 행동 시퀀스와 dominant option이 일치할 때만 옵션을 학습하고, 불일치하면 'stop' 신호로 옵션 종료를 학습함.
![[75a972e57ff1e718c23a94a270333103.webp.mp4]]
철권의 콤보 같은 것이 dominant option에 해당한다.
dominant option
s.t
option network. 위에 해당하는 dominant option을 찾아 내는 것을 목표로한다.
maximum option length
이때, dominant option은
주어진 최대 option 길이 L에 대하여,
MCTS 에서 Dominant option으로 planning하기
dynamics network
기본적인 구조는 MCTS와 같으나, 옵션을 이용하므로, 여러 노드를 한 번에 건너뛸 수 있는 옵션 엣지(Edge)를 추가하여, action과 함께 option을 통합할 수 있다.
트리의 각 엣지는 다음 통계를 가진다.
각각 방문 횟수(N), 추정 Q값, 사전확률(P), 보상(R)이다.
primitive edge의 통계는 option edge의 통계를 포함한다.(Muzero와 동일)
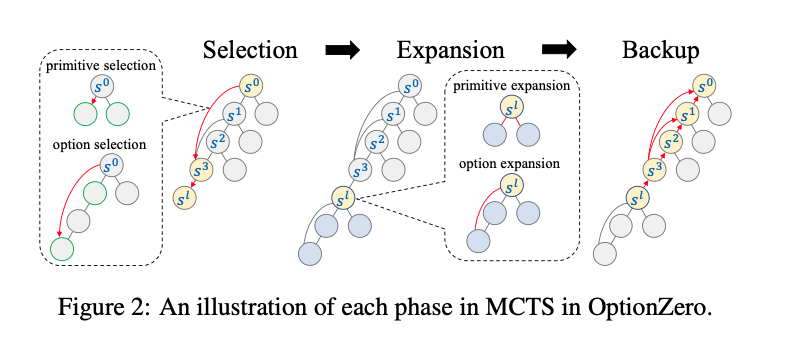
Selection
Expansion
Backup
실험 결과
GridWorld
-
초반 primitive action만 쓰다가, 학습이 진행되며 점차 긴 옵션을 스스로 학습.
-
최종적으로 30step짜리 행동을 4개의 option으로 해결. 학습 및 수행 효율 7배 증가
Atari Games -
26개 Atari 게임 실험
-
옵션 길이 L=3, L=6 설정해 비교: 옵션 쓸 때 Mean Human-normalized score가 MuZero 대비 1.31 오름.(922%-> 1054%)
-
다양한 게임에서 옵션이 주로 반복 액션이거나 특정 상황에서 복합적인 액션 등도 학습함.(반복행동, 콤보)
-
옵션은 무작정 쓰지 않고, 게임 특성따라 전략적으로 씀.
-
Atari의 경우 전체 행동의 30~40% 옵션 사용.
-
옵션을 플래닝에만 쓰고, 실제 실행은 primitive action만 해도 성능이 많이 향상되었으나,
-
환경이 지나치게 복잡하거나, 옵션이 너무 다양하면 dynamics 네트워크 학습이 어려워지는 한계가 있었음.
-
향후 연구에서 동적인 옵션 길이 설정 방법 탐색 필요