새로 제안한 개념들.
contextual layer.
context에 관한 처리를 하는 레이어. transformer의 self-attention layer 역할 등을 일반화하여 생각
: 기본적으로 single vector 를 input으로 받는 함수, 선택적으로 추가적인 context 를 받을 수도 있다.(sequence of tokens, image etc). so, output - 간단하게
이때, 는 self-attention layer(transformer의 경우)의 output을 통해서, 와 같은 vector space를 점유하므로, 다음과 같이 contextual vector를 정의할 수 있다.
contextual block.
contextual block 는 contextual layer 와 neural network 의 합성함수이다.
추가로, 이다. 논의에서 layer 개수 안 중요하다는 것. 모든 dense-layer 포함하는 개념
Theorem 2.2
contexual block 는 weight matrix 를 포함하는 fully connected layer 와 contexual layer 로 구성되어있다. 주어진 context 와 input 에 대해, 인 가 에 미치는 효과는 의 첫번째 레이어에 대한 rank 1 업데이트 에 암묵적으로 대응된다.
수식적으로는 다음과 같다.
이때, 는 에 대응하는 context vector이다. 또한, 의 rank는 1이다. 는 Y에 속하지 않는 모든 C의 원소 집합이다.
논문에 증명이 함께 써있는데, 간단하니 재료만 써 두면,
2.2의 와 의 정의를 통해 구할 수 있다.
다시 말하자면,
어떤 contextual layer라도, prompt로 부터 첫번째 신경망 층의 implicit weight transfer를 만들어 냄이라고 해석할 수 있다. contextual layer는 self-attention, RNN, local attention을 활용하는 recurrent layer 등이 있다. Y=C면 다음과 같이 쓸 수 있다.
where, context vector , 는 rank 1이다.
Appendix A에는 skip-connection 일반화한 거 있는데 이거는 정리를 추가로 해보자. 는 any differential model.
이 식들을 가지고 아까보다는 귀찮지만, 풀면 풀린다.
이러면, 최근 세 논문에서 제안된 몇가지 개념과 이 연결된다고 하는데... 인용된 논문의 개념들은 이 논문의 Appendix A 말미의 인용을 참고하시길 바란다.
또한 pre-LN 트랜스포머 블록, 로컬 어텐션을 이용하는 Griffin recurrent model 등에도 적용이 가능해지는 것이다.
The implicit learning dynamics of ICL
sequence of tokens
위의 표기를 반복 적용하면, implicit dynamics가 드러나게 된다.
초기 가중치 , NN의 첫 dense layer
이때, 에 대해 수렴하는 weight를 다음과 같이 표기하면,
아래와 같아진다.
이걸 online gradient descent 학습 역학과 비교하여 Proposition 3.1을 얻는다.
토큰을 데이터 포인트로 고려하는 것이다.
proposition 3.1
learning rate 이고, step 에서의 loss는 이다.
where,
를 정리한 식을 정리하면, 쉽게 아래 식을 유도가능하다.
이때, 이다.
직관적으로 는 번째의 컨텍스트 토큰이 추가되는 효과를 측정하는 것이다.
Appendix B에서는 각 단계마다 변화하지 않는 다른 형태인 dynamics를 기술하는데, 이건 분해 공식을 통해 얻는다.
iteration 가능하니...
따라서 context C가 x에 미치는 영향은
실험
기존 ICL 관련 이론을 살펴보지 않았지만, 본 논문에 제안된 이론을 통해 더 적은 제약 조건으로 contextual layer와 NN 조합으로 만들어지는 Context block의 dynamics를 기술할 수 있다는 것을 알았다.
그 방식은 context 토큰을 데이터 포인트로 보고, 첫 번째 context block의 학습으로서 표현하는 것이다.
정리 2.2에 관하여, 프롬프트가 주어졌을 때 예측 이, 프롬프트 없이도 rank 1이었던 를 MLP에 적용한 예측 와 사실상 동일함을 보이는 것이 목적이다.
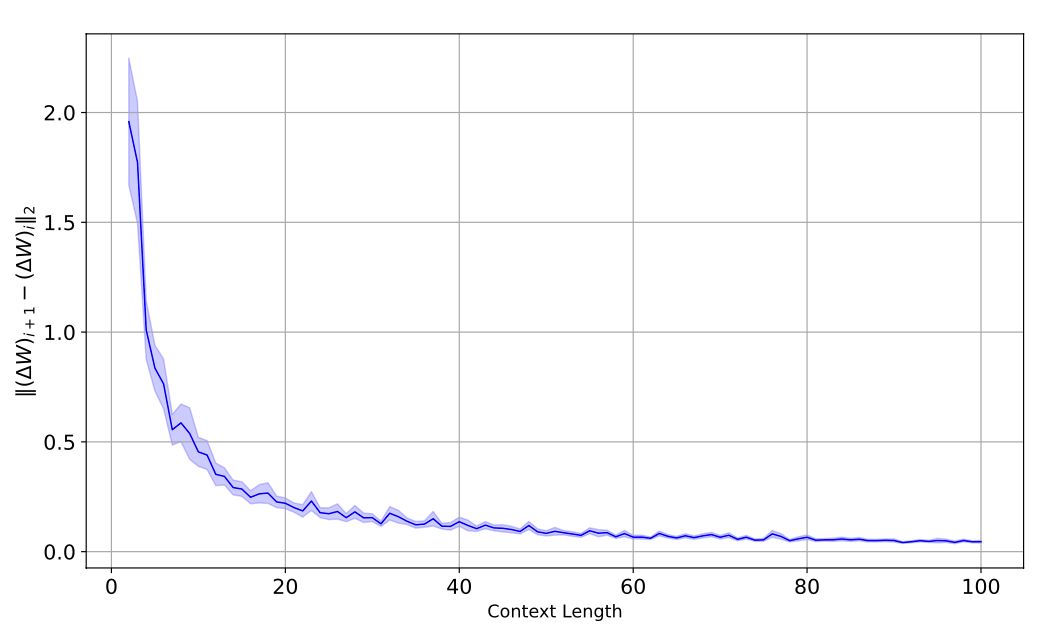
이때, 는 context token을 순차로 학습하면서 정의되는데, 이것이 소멸하는지.(수렴하는지)를 측정하여, 이러한 Dynamics가 동작하는 지 확인하는 것이다.
프롬프트는 이고, 이때,
모델은 하나의 트랜스포머 블록에, MLP skip connection 제거.
예측은 query토큰 출력의 마지막 성분.
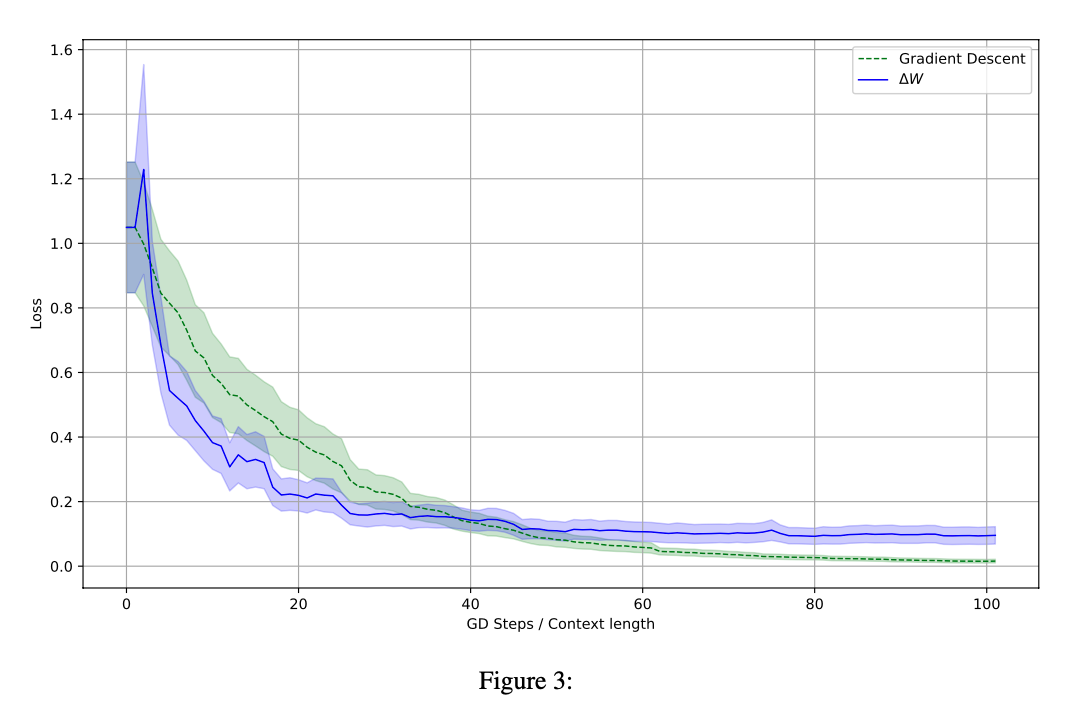
결과적으로 i가 커질수록, 가 감소하고 소멸하였다. 이러한 수렴성은 경사하강법의 Dynamics와 유사하게 나타났다. (batch loss가 )
pretrain 후 새롭게 만든 세트에서 앞 개의 예시만으로 SGD 파인튜닝을 수행하여, test loss를 계산한 결과와, 를 계산하여 얻은 test loss와 비교해도, 100회 평균 서로 유사하게 loss를 줄여나갔음.
한계:
단일 블록, 마지막 입력토큰의 출력과 첫 생성 토큰에 한정된 등가성.
제한적인 실험 세팅.