Overview
- Reference: [https://arxiv.org/abs/2310.16834, https://github.com/louaaron/Score-Entropy-Discrete-Diffusion]
- https://aaronlou.com/blog/2024/discrete-diffusion/
- Why this paper?:diffusion model 을 언어 데이터와 같은 discrete 데이터에 적용하기 위해 diffusion 모델의 기본이론인 score matching을 discrete structure에도 일반화함. empirical 하게 어느정도 성과를 거둠.
- Core Question/Purpose: 확산 모델을 언어 데이터에 어떻게 적용할 수 있을까? 기존 auto-regressive 모델과 경쟁할 수 있을까?
Summary
-
High-Level Summary:
기존의 diffusion model은 자연어와 같은 discrete data에서 성능이 부족함. 이를 해결하기 위해 이 논문에선 기존 diffusion model의 loss인 'Score Entropy'를 discrete space에 일반화하여, Score Entropy Discrete Diffusion(SEDD)를 개발함. SEDD 모델은 기존 language diffusion model 대비 perplexity를 크게 낮추고 GPT-2 수준의 성능을 보임.auto-regressive 모델이 자연어와 같은 이산 구조 데이터에 전부이고, 더 많은 데이터와 하이퍼 파라미터가 필요하다고 말했지만, 이는, 1. controll(생성과정 중 데이터 분포에서이탈, drift한다.)이 어렵고, 2. inference하면 토큰마다 생성하니 병렬화가 어려우며, 3. 단방향으로 작업이 진행되어, 앞 단어, 뒤 단어가 지정하는 등의 제어를 하기 매우 어렵다. 따라서 SEDD를 제안한다.
에너지 기반 모델의 문제는 Z를 아는 것이 매우매우 어렵다는 것이다.
를 직접 모델링 하는 대신 를 모델링 한다.
이러면 Z 를 제거 가능하니까..
따라서
이것은 유명한 연속공간 score function
중요하게. 우리는 신경망 근사를
이를
Cross entropy loss이용
Score entropy
data 분포가 아니라
노이즈란 무엇인가?
연속공간은 가우시안 노이즈 때리지만, 이산공간은 다른 요소를 jump해야함
1. Intro
1.1 Background
- text generation 분야에선 auto-regressive model이 경쟁력있는 방법으로 자리 잡고 있음.
- 하지만, auto-regressive model은 느린 샘플링 속도, 제어의 어려움, 성능 저하로 인한 분포 조정의 필요 등의 한계를 보임.
- 이미지 도메인에서 성공한 diffusion 모델을 자연어 분야에 적용하려는 시도가 있음.
2. Preliminaries
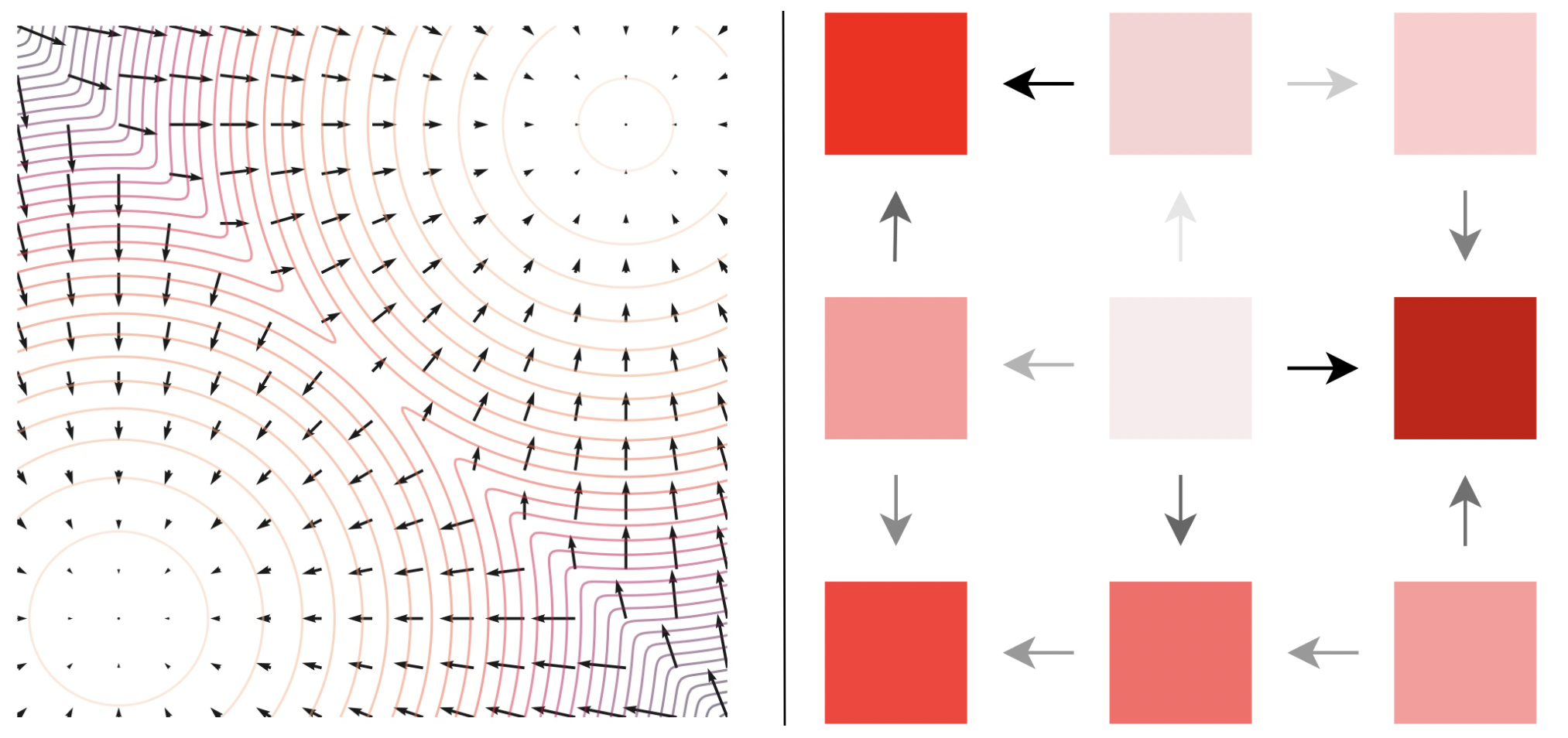
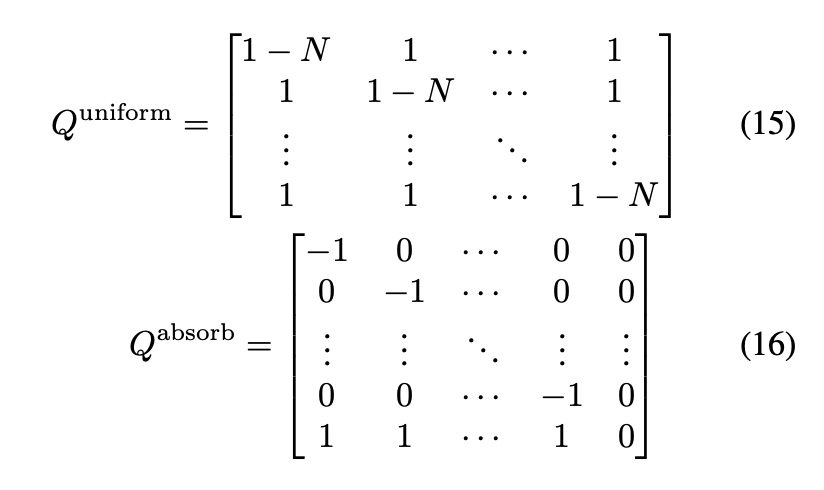
2.1 Discrete Diffusion Processes
- discrete data에 대한 Diffusion Processs는 Continuous time Markov chain으로 정의됨. 이는 diffusion matrix
를 통해 정의됨. -
이 확산 과정은 아주 작은
를 이용한 오일러 간격으로 근사하여 시뮬레이션 가능하며, reverse-diffusion matrix는 diffusion matrix의 probablity ratio ( )로 정의할 수 있음. 이는 특정 score function 을 일반화한 것이다. -이때 discrete structure에서 gradient operator는
인 로 다음과 같이 정의된다. score function 은 normalize된 gradient를 일반화한다.
-
2.2 Discrete Diffusion Models
- discrete diffusion model 은 reverse diffusion 과정에서 데이터 분포의 ratio를 학습하는 것을 목표로 한다.
- discrete space에서는 기존 continuous diffusion model에서 사용하던 Score matching이 명확히 확립되지 않아 다양한 방법론이 혼재해있었다.
- 이제 그것들 분석하고 이론적, 경험적 한계를 지적할거다.
Mean prediction
- ratio
를 직접적으로 매개변수화 하는 것이 아니라, reverse diffusion dentity 를 학습하여 간접적으로 ratio를 얻는다. - objective가 continuous time에서 명확하지 않고 근사가 필요하며, 밀도를 직접학습하는 것은 난이도가 높아, 이 방법은 실제 성능이 크게 낮았다.
Ratio Matching
- dimension 별로 marginal probability들을 maximum likelihood 방식으로 학습한다.
- 이 방법은 표준적인 score matching과 크게 벗어나고, 특별하고 비싼 신경망 구조를 필요로 한다.
- 결과적으로 Mean Prediction 보다 성능이 떨어진다.
Concrete Score Matching
- 기존의 Fisher divergence를 일반화한 접근법이다.
- 이 방법은 probability ratio 근사를 목표로하지만,
가 양수여야하는 조건과 loss의 불일치로 인해 수렴하지 않는 문제점이 있다. - 이론적 배경에도 불구하고 성과가 부족하다.
학습하는 것 :
appendix.D
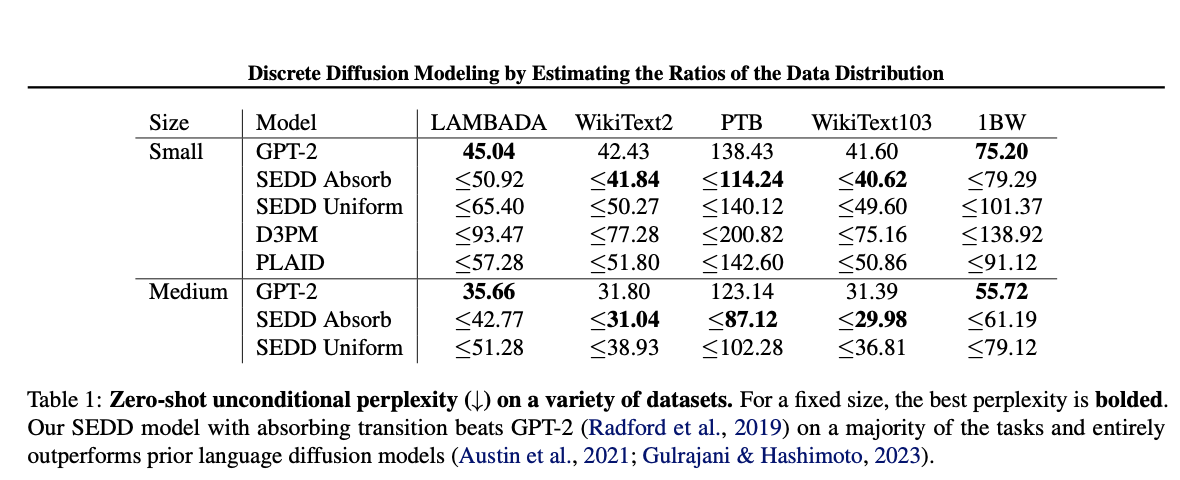
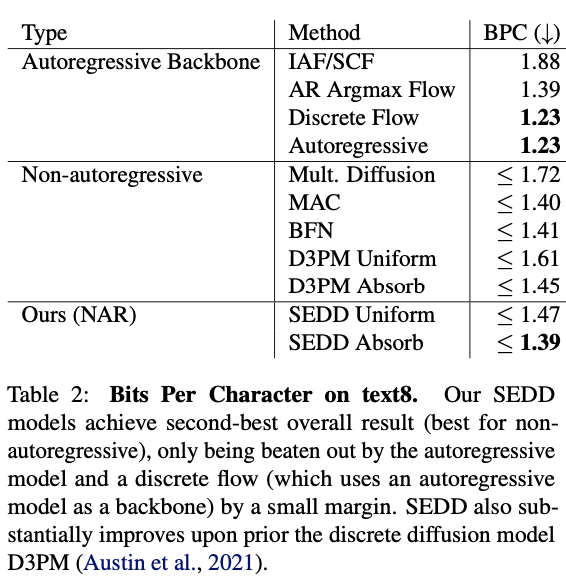
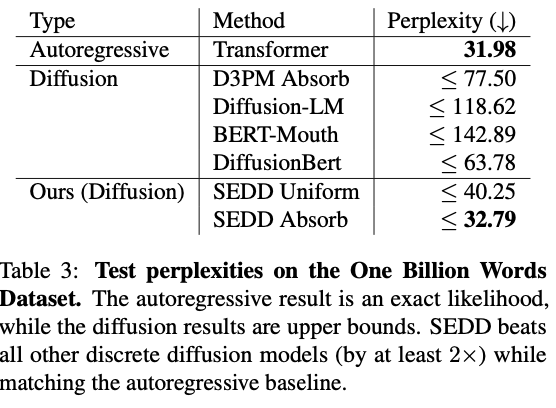
Concrete score matching 쓴거 GPT2 랑 score entropy랑 비교했는데 likelihood loss 3~4배,
perplexity는 만배 커짐. -> 수렴 잘 안됨.
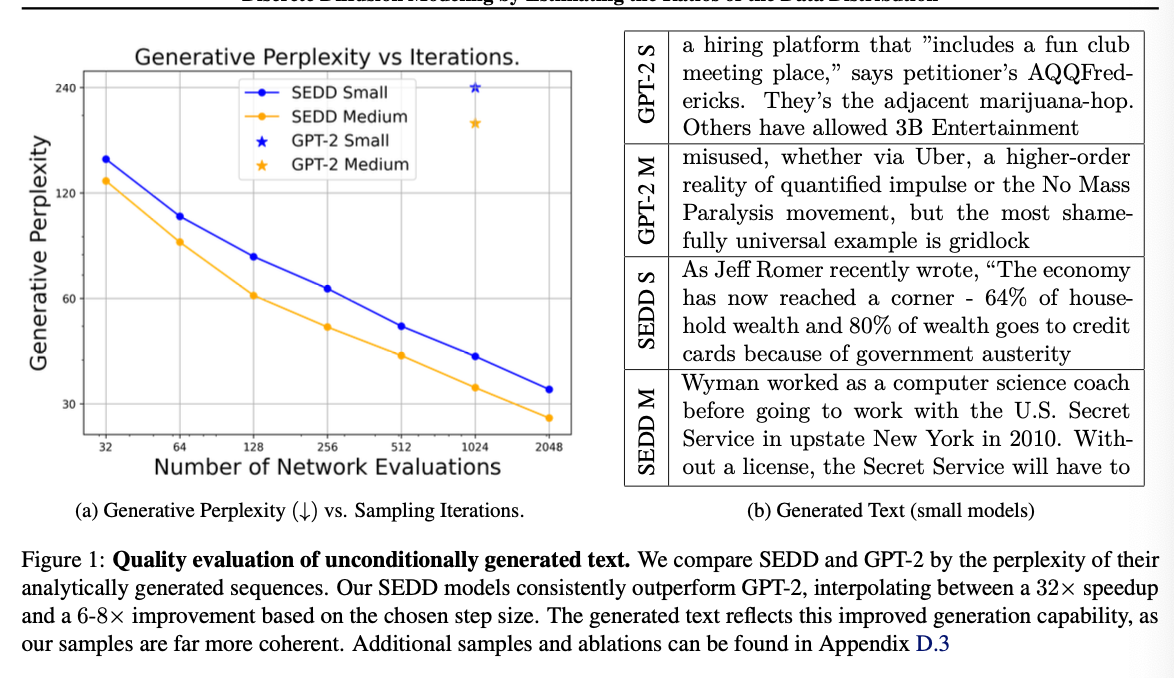
Generative perplexity 평가
D.2. Further Evaluation of Generative Perplexity
We further evaluate our generative perplexity for uniform models as well as different sampling schemes (analytic sampling based on Tweedie’s vs Euler sampling based off of reverse diffusion). Results are shown in Figure 2. Generally, we find that uniform does not produce the same linear tradeoff curve as absorbing (most likely due to a bottleneck in generation quality). Futhermore, analytic generally outperforms Euler sampling, and this is a major factor for the uniform model.
We also generated on our trained baselines (Austin et al., 2021; Gulrajani & Hashimoto, 2023), finding both performed substantially worse than our SEDD Absorb baseline but slightly better than our SEDD Uniform.
Tweedie 이론이랑 Euler 방식 비교
Analytic 방식이 Euler 방식 보다 샘플링 성능(perplexity)가 괜찮았따. 몇가지 모델로도 더 해봤는데, SEDD absorb보다는 성능이 안좋았지만 SEDD uniform 보다는 좋았따.
Score Entropy Discrete Diffusion Models
- Score entropy는 Concrete Score Matching과 달리 목표로 하는 probability ratio의 양수 조건을 discrete diffusion 과정에서 만족하도록 설계했다.
는 0보다 크거나 같고, 는 score network이다. K(a)는 로 를 0보다 항상 크거나 같게 할 수 있도록 해주는 normalizing constant function이다.
Fisher Divergence 대신 Bregman divergence를 이용한다.
따라서 non-negative, symmetric, convex하다. 그리고 기존 cross entropy 도 general positive value로 일반화 할 수 있다.
Score Entropy Properties
Score entropy는 ground truth concrete score를 포함하는 적절한(suitable) loss function이다.
가 이고 fully support 된다고 가정해보자. 데이터의 수와 model capacity가 무한하다면, 최적의 파라미터 는 위 cross entropy를 최소화하고, 다시말해 를 모든 pair에 대해 만족한다. 그리고 loss는 0이된다.
score entropy는 문제가 되는 gradients를 rescaling 함으로써 concrete score 보다 직접적으로 낫다.
concrete score matching과 같이 score entropy는 모르는
는 에 영향을 안주는 상수항을 제외하면, implicit score entropy와 동일한데,
-$$\mathcal{L}{ISE}=\mathbf E{x \sim p} \bigg [\sum_{y \neq x} w_{xy}s_\theta(x)y - wlog \space s_\theta(x)_y \bigg]$$- 근데 이거 몬테카를로 식으로 추정하려면, x 샘플링해서 x당 가능한 모든 y에 대해
를 해야한다. 근데 고차에선 이 연산이 비현실적으로 복잡하기에, y를 uniform하게 sampling할 수 밖에 없다. 하지만 이러면 Hutchinson trace estimaotr에서 말한 추가적인 variance 와 유사한 문제가 생기게 된다. 이로 인해 ISE는 대규모 데이터에서는 부적합하다. 따라서 Vincent의 denoising score matching 형태의 변형된 Score Entropy를 이용한다.
Denoising Score Entropy
transition kernal
얘는 몬테카를로 샘플링 할때, 하나의
Likelihood Bound For Score Entropy Discrete Diffusion
ELBO를 정의할거임. -> likelihood-기반 학습과 평가에 필요함.
dependent score network
그리고 parameterized densities
diffusion 그리고 forward probabilities가 위에 구해졌으므로...
여기서
식으로는.
DWDSE 디자인 해설
Remark. The DWDSE (and the implicit version) can be derived from the general framework of Benton et al. (2022) assuming a concrete score parameterization. In particu- lar, the implicit version coincides with the likelihood loss introduced in Campbell et al. (2022).
그리고 얘는 고차원 task 에서도 유지됨.
우리가
근데 문제는 Q는 확산과정이므로,
4. Simulating Reverse Diffusion with Concrete Scores
Campbell(A continuous time framework for discrete denoising models)에
given a sequence
근데
true denoiser는
근데 모든 ratio 모르고ㅗ 오직 Hamming distance 가 1인 시퀀스만 파악할 수 있기 때문에 token transition probabilities를 다음과 같이 작성함.(for
(Tweedie τ-leaping). Let
그리고

결과